The Evolution of the Newsletter: Building the AI-Driven Real Estate Research Engine
The Evolution of the Newsletter: Building the AI-Driven Real Estate Research Engine
What started as an idea for a standard real estate blog has quickly transformed into something far more sophisticated: an AI-driven Real Estate Research Engine. We are no longer planning to merely write about market trends; we are in the process of constructing an autonomous pipeline designed to ingest the entire real estate environment, analyze it, and produce high-quality, professional reports daily.
Right now, we are fully immersed in the construction phase, laying the technical foundation and letting curiosity guide our engineering choices.
The Blueprint: Building the Autonomous Core
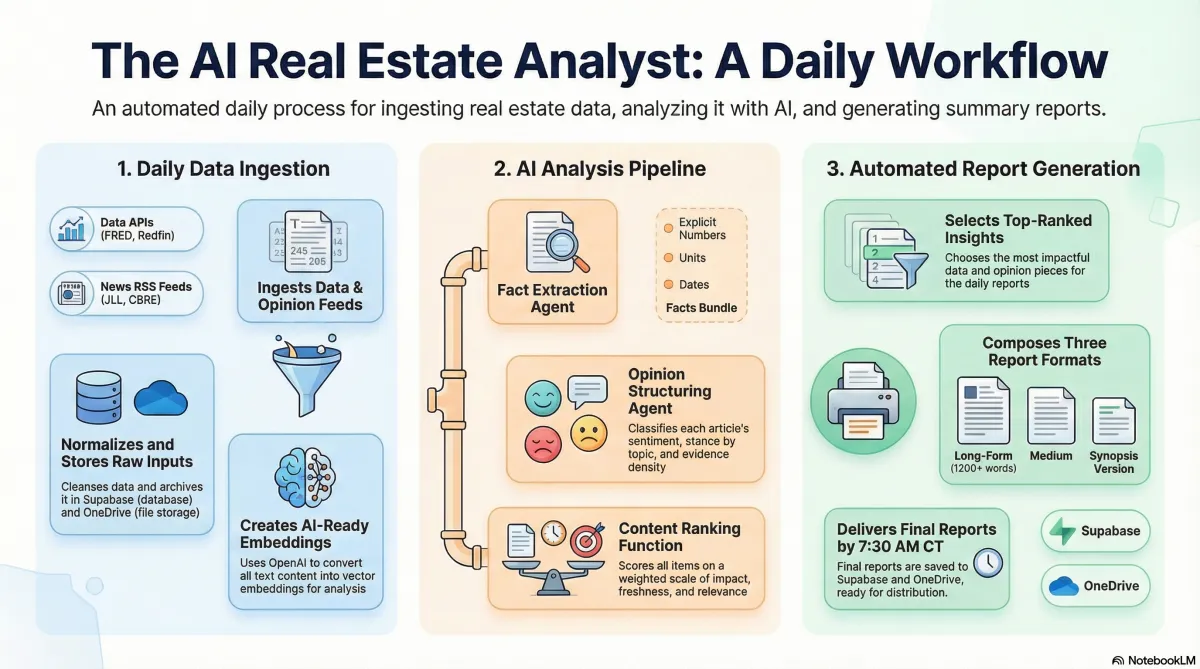
We have moved beyond simple concept documents and are actively defining the architecture of this automated system. This is a massive project, and the foundation is critical.
We are establishing the core n8n Orchestrator, which will manage the three daily workflows necessary for the engine to operate: Ingest, Analyze & Rank, and Compose. This Orchestrator is the conductor that makes sure all the pieces—the LLM agents (the Brain), the Supabase database (the Memory), and the file archive in OneDrive—work together seamlessly.
Our immediate focus is setting up the Phase 1 Environment. We are currently defining the SQL schema for tables like documents and timeseries within Supabase, and configuring the workflow logic to handle the initial data feeds, such as the official mortgage rates from FRED (Federal Reserve Economic Data). We are building a system that is modular, observable, and secure, ensuring that as we expand, we can do so robustly.
The Curiosity: What Happens After Ingestion?
The technical build-out is driven by a profound curiosity: Can we truly automate the synthesis of complex, verified real estate intelligence?
Our engine is designed to handle two distinct types of inputs:
Hard Data (the "What"): Pulling foundational metrics like mortgage applications from the MBA and benchmark yields.
Opinion & Commentary (the "Why"): Drawn from high-signal sources like Calculated Risk, HousingWire, and research from major firms like CBRE.
The real engine begins when our analysis agents take over in a process called Multi-Stage Refinement. We don't want weak summaries; we want facts. The system uses agents for dedicated Fact Extraction, isolating specific numbers, units, and dates into a "facts bundle."
Crucially, opinions are not treated equally. We are building a sophisticated Ranking function that scores commentary based on factors like freshness, influencer authority, and evidence density, while actively penalizing content that is deemed sensationalism.
This commitment to rigor leads to our most stringent success criteria: Citation Validation. Our pipeline is designed to check every numeric citation in the final report, and if a mismatch is found, the report will be rejected, forcing the LLM to regenerate the content until the numbers trace directly to their source URLs and dates.
Looking Ahead: Verified Reports, Daily
This entire apparatus is designed to culminate in the final output: three distinct reports delivered every single morning by 07:30 CT:
Long-form deep dive (1,200–2,000 words)
Medium summary (400–700 words)
Quick Synopsis (5–8 bullets)
We are building this engine piece by piece, securing credentials, setting up the archives, and writing the logic that will govern the agents. We are excited about the potential of a system that guarantees verified facts and balanced analysis, and we are curious to see the sophisticated level of autonomous intelligence that emerges once the final pieces of this architecture are locked into place.

